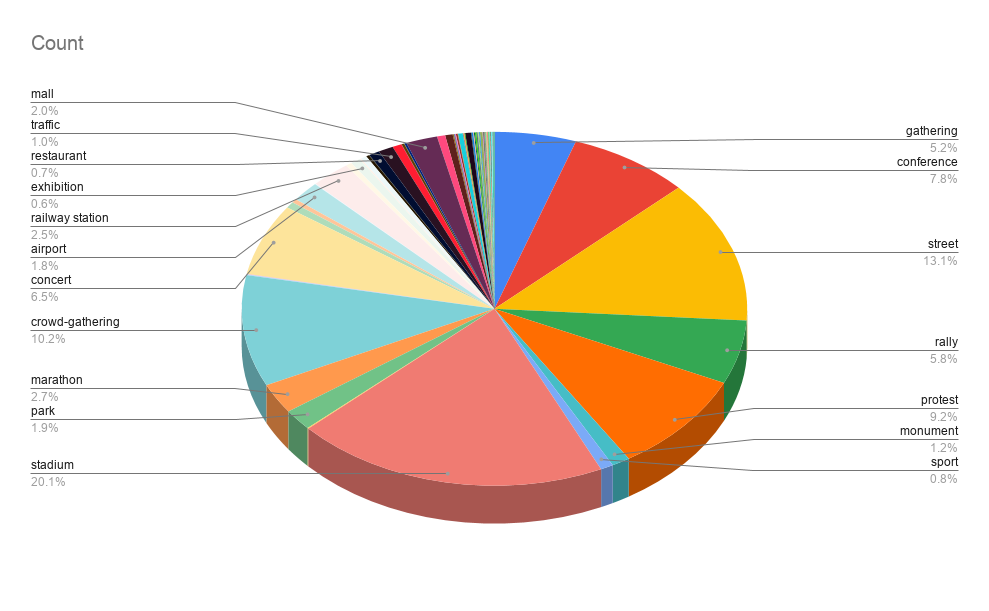
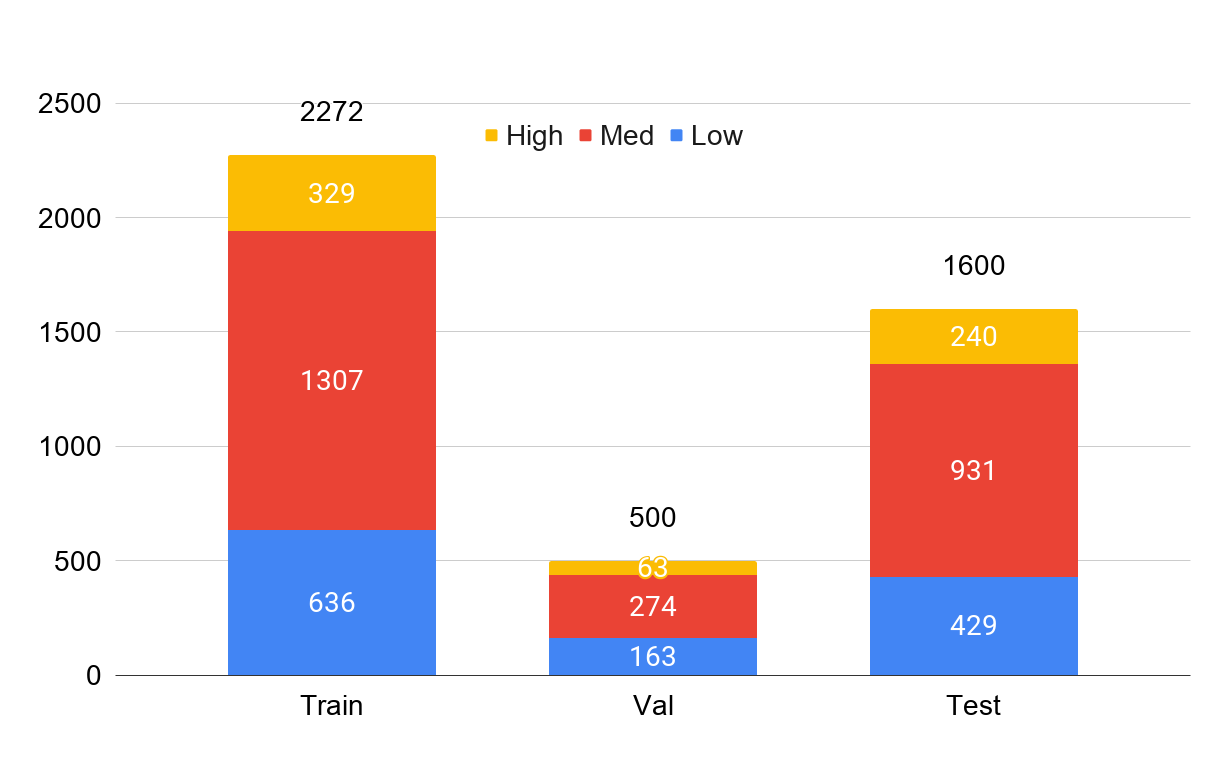
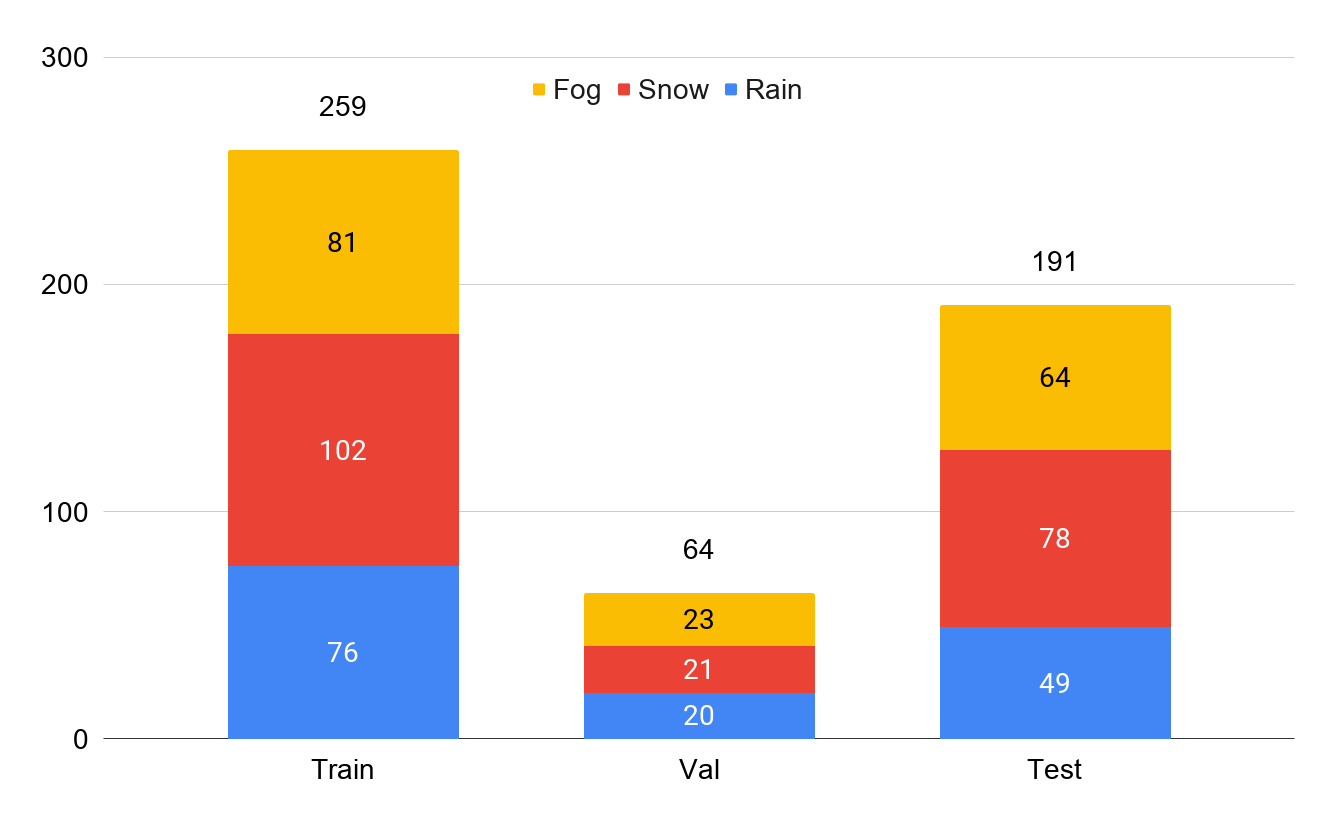
Image Highlights
Diverse Conditions: varying densities, illumination variations, adverse weather conditions such as fog, rain and snow.

Low density

Medium Density

High Density

Fog

Rain

Snow

Low illumination

Night time

Distractor